Biochemistry: Nucleic Acids Exam
Test your knowledge with these 40 questions.
Nucleic Acids Exam
Question 1/40
Exam Complete!
Here are your results, .
Your Score
38/40
95%
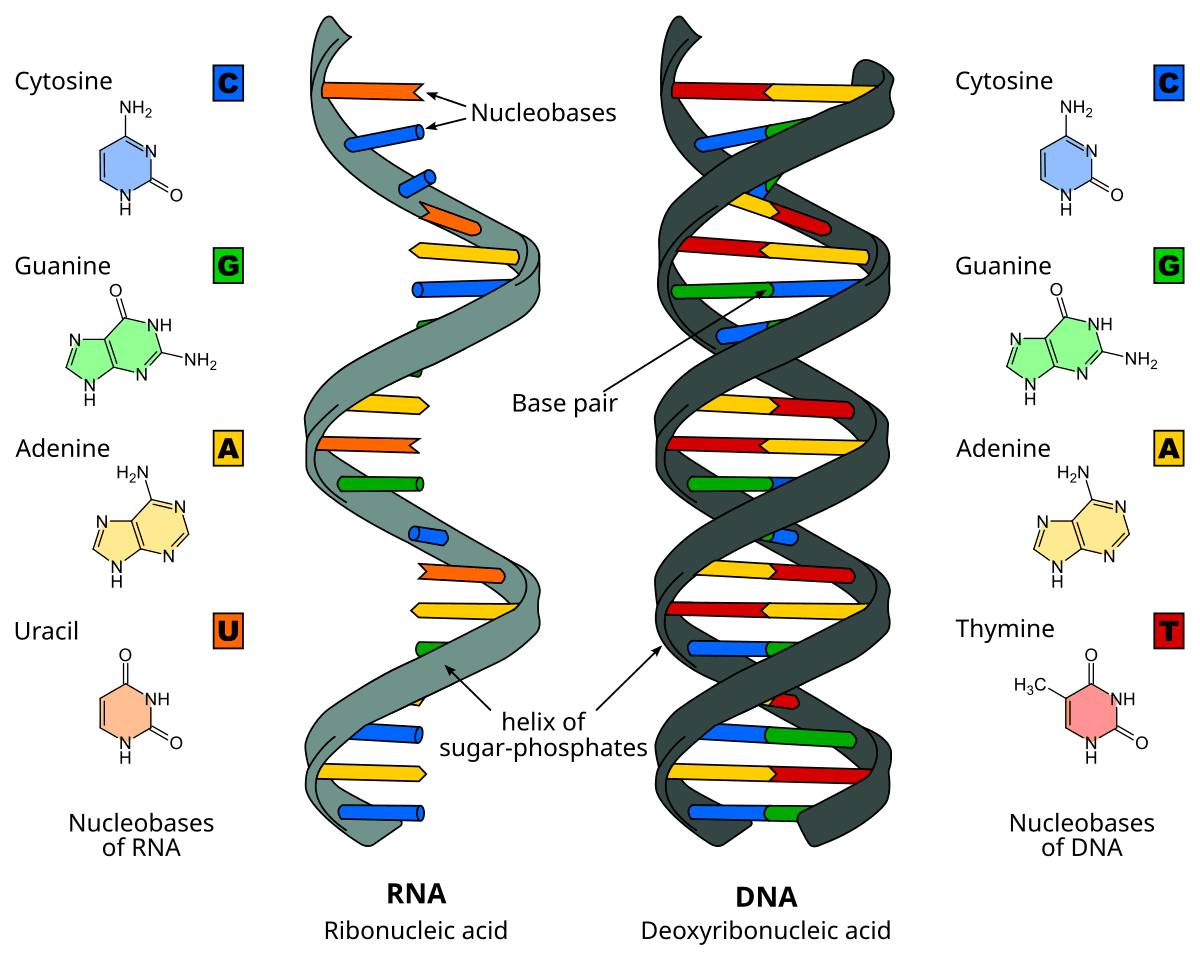
Test your knowledge with these 40 questions.
Question 1/40
Here are your results, .
Your Score
38/40
95%
Test your knowledge with these 30 questions.
Question 1/30
Here are your results, .
Your Score
28/30
93%
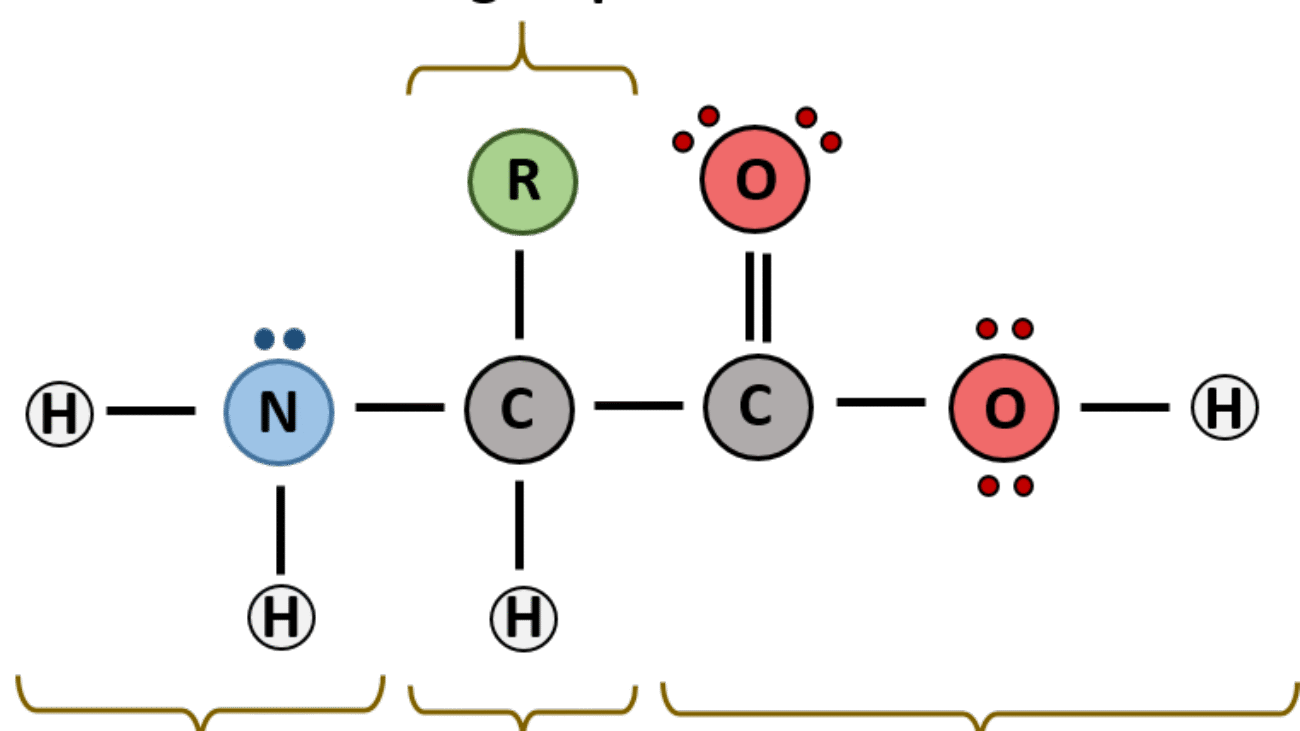
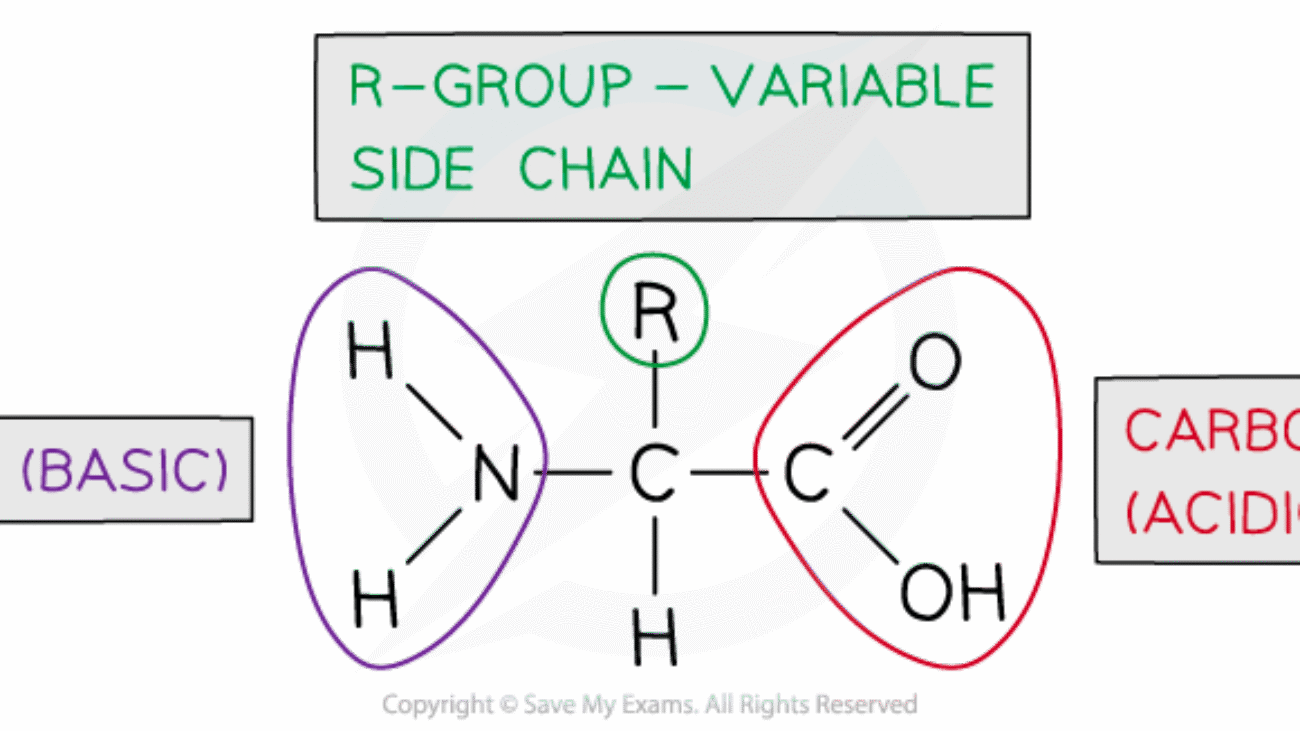
A peptide or protein sequence is the specific linear order of amino acids linked together by peptide bonds. There are very specific conventions for how these sequences are written and read, which are essential for clear, unambiguous communication in biochemistry and molecular biology.
Every peptide or polypeptide chain exhibits a distinct directionality, meaning it has a defined "start" and an "end." This intrinsic polarity is fundamental to how proteins are synthesized, fold, and function.
Peptide sequences are always read from left to right, starting from the N-terminus and proceeding sequentially towards the C-terminus.
Each amino acid unit within the peptide chain, after forming peptide bonds, is referred to as an amino acid residue. This term emphasizes that each amino acid has lost the elements of water (a hydrogen atom from its amino group and a hydroxyl group from its carboxyl group) when participating in the formation of a peptide bond. Within the chain, only the R-group and the α-carbon, along with parts of the backbone, remain.
To simplify the writing and reading of often very long protein sequences, standard abbreviations are universally used for the 20 common genetically encoded amino acids:
| Amino Acid | Three-Letter Code | One-Letter Code |
|---|---|---|
| Alanine | Ala | A |
| Arginine | Arg | R |
| Asparagine | Asn | N |
| Aspartate | Asp | D |
| Cysteine | Cys | C |
| Glutamine | Gln | Q |
| Glutamate | Glu | E |
| Glycine | Gly | G |
| Histidine | His | H |
| Isoleucine | Ile | I |
| Leucine | Leu | L |
| Lysine | Lys | K |
| Methionine | Met | M |
| Phenylalanine | Phe | F |
| Proline | Pro | P |
| Serine | Ser | S |
| Threonine | Thr | T |
| Tryptophan | Trp | W |
| Tyrosine | Tyr | Y |
| Valine | Val | V |
Note: For cases where the exact amide status is unknown or ambiguous:
When asked to "name" a peptide or write its sequence, you list the amino acid residues in order from the N-terminus to the C-terminus, using their standard abbreviations.
Let's carefully examine this peptide structure to determine its sequence.
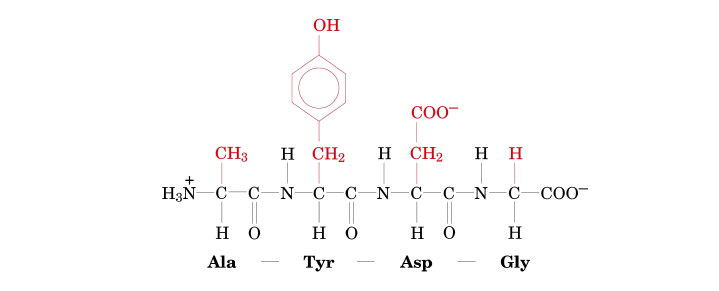
Step-by-step identification:
Test your knowledge with these 40 questions.
Question 1/40
Here are your results, .
Your Score
38/40
95%

Test your knowledge with these 51 questions.
Question 1/51
Here are your results, .
Your Score
48/51
94%
Test your knowledge with these 30 questions.
Question 1/30
Here are your results, .
Your Score
28/30
93%
Test your knowledge with these 40 questions.
Question 1/40
Here are your results, .
Your Score
38/40
95%
Test your knowledge with these 40 questions.
Question 1/40
Here are your results, .
Your Score
38/40
95%
A 2-year-old boy from Mukono district presents with recurrent episodes of severe bone pain (hands, feet, and sternum pain), jaundice, and fatigue for 3 days.
Laboratory findings reveal:
A diagnosis of Vaso-occlusive crisis, and severe anaemia in Sickle Cell Disease was made.
This part requires a detailed breakdown of the specific molecular error in the patient's haemoglobin protein, focusing on the identity of the amino acids and the genetic origin of the mistake.
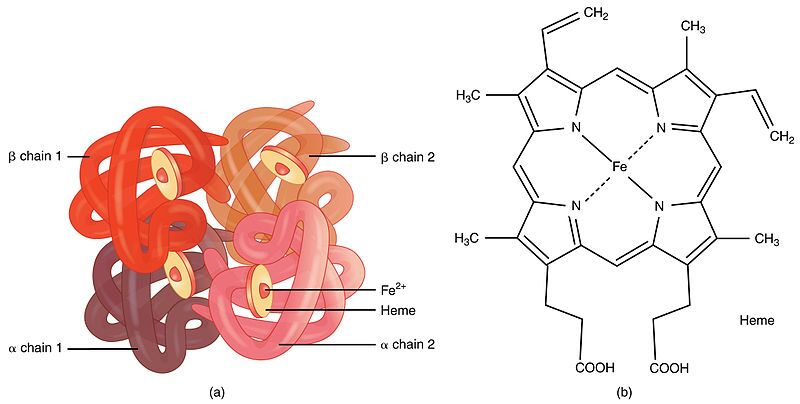
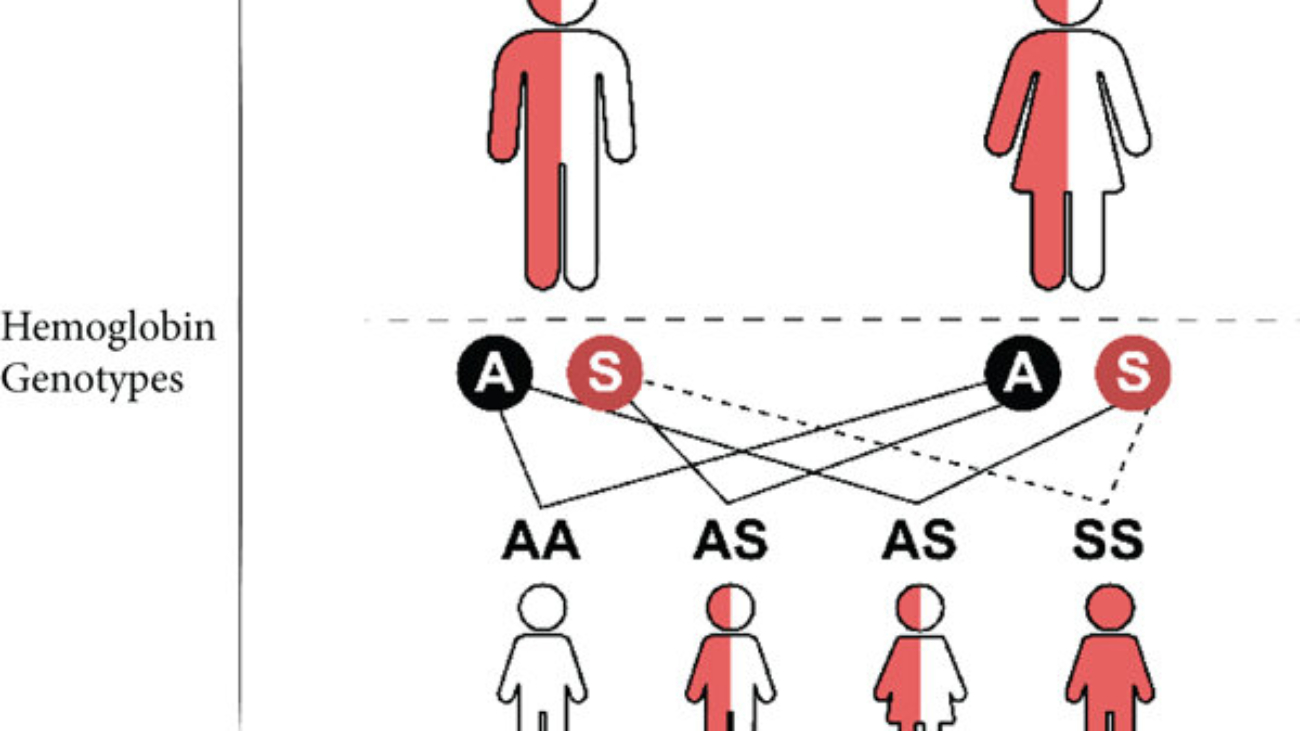
First, it's important to understand what haemoglobin is. Haemoglobin is the primary protein found within red blood cells (erythrocytes) and its main function is to transport oxygen from the lungs to the body's tissues. It is a large, complex protein with a quaternary structure, meaning it is composed of multiple polypeptide subunits. A normal adult haemoglobin molecule (HbA) is a tetramer, consisting of four chains: two identical alpha (α)-globin chains and two identical beta (β)-globin chains. The genetic defect in sickle cell disease specifically affects the gene that provides the instructions for the beta-globin chain.

The defining molecular event in sickle cell disease is a single amino acid substitution at a precise location within the beta-globin polypeptide chain.
In a person with normal adult haemoglobin (HbA), the amino acid at the sixth position from the beginning (the N-terminus) of the beta-globin chain is Glutamic Acid (abbreviated as Glu or E).
In this patient with sickle cell disease, the haemoglobin is abnormal (called HbS). At that exact same sixth position, the Glutamic Acid has been replaced by the amino acid Valine (abbreviated as Val or V).
This single change, Glu6Val, is the sole cause of the disease.

The severity of this substitution is due to the drastically different chemical "personalities" of the R-groups (side chains) of Glutamic Acid and Valine. This position is on the outer surface of the protein, where it is exposed to the watery environment inside the red blood cell.
| Amino Acid | Chemical Class & Properties | Behavior in Water |
|---|---|---|
| Glutamic Acid (Normal) | Its side chain contains a carboxyl group (`-CH₂-CH₂-COOH`). At the neutral pH inside a red blood cell (~7.4), this group loses a proton and becomes negatively charged (`-COO⁻`). Therefore, it is an acidic, polar, and charged amino acid. | Because it is charged and polar, Glutamic Acid is hydrophilic ("water-loving"). It forms favorable interactions with polar water molecules and is perfectly stable on the protein's surface. |
| Valine (Mutant) | Its side chain is an isopropyl group (`-CH(CH₃)₂`), which is a small, branched structure made only of carbon and hydrogen. These bonds are nonpolar. Therefore, Valine is a nonpolar, aliphatic, and neutral amino acid. | Because it is nonpolar, Valine is hydrophobic ("water-fearing"). It is thermodynamically unfavorable for this "oily" side chain to be exposed to water. It will seek to interact with other nonpolar groups to hide from the aqueous environment. |
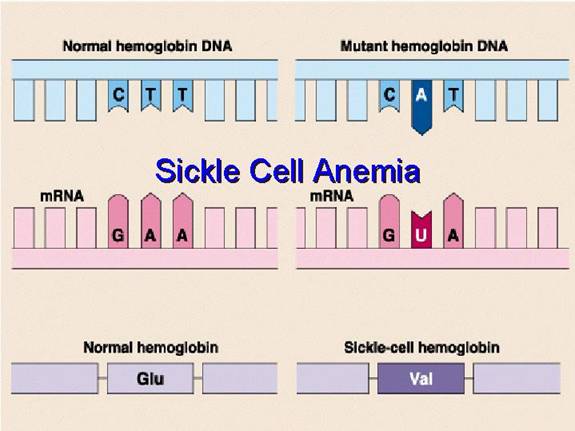
This amino acid error originates from a single change in the DNA sequence of the beta-globin gene. This type of mutation is called a point mutation, specifically a missense mutation because it results in a codon that codes for a different amino acid.
Therefore, a single DNA base change leads to a single mRNA codon change, which in turn leads to the single, catastrophic amino acid substitution that defines sickle cell disease.
This section explains the step-by-step process of how the single Glu6Val substitution causes the haemoglobin to malfunction and leads to the patient's observed symptoms.

The key event is the behavior of HbS when it is in the deoxygenated state. In the oxygenated state (in the lungs), HbS functions almost normally as an oxygen carrier.
Shape Distortion: These long, stiff haemoglobin polymers grow to be longer than the diameter of the red blood cell itself. They physically push against the cell membrane from the inside, distorting the cell from its normal, flexible biconcave disc shape into a rigid, elongated, crescent or "sickle" shape.
Loss of Deformability: This sickling process causes a dramatic loss of the cell's flexibility. It becomes hard and unable to deform. This process is initially reversible if the cell becomes reoxygenated, but repeated sickling events cause permanent membrane damage, leading to irreversibly sickled cells.
The physical properties of these sickled cells are directly responsible for the patient's symptoms:
Knowing that the core problem is a hydrophobic amino acid causing polymerization allows for the design of targeted therapies.
This approach aims to reduce the relative concentration of the problematic HbS.
This is the most direct chemical approach, aiming to stop the Valine from interacting with its target.
This is the most fundamental approach, aiming to fix the DNA instruction so the correct amino acid is made.

Test your knowledge with these 25 questions.
Question 1/25
Here are your results, .
Your Score
23/25
92%
Test your knowledge with these 51 questions.
Question 1/51
Here are your results, .
Your Score
48/51
94%